
An introduction to Large Language Models (LLMs), their role in AI-driven interactions, and the power of prompt engineering to create more human-like, efficient conversational AI systems.

In the ever-evolving landscape of artificial intelligence, the development of ChatGPT stands as a monumental achievement. Trained on over 500 gigabytes of text data sourced from the internet, this advanced language model represents a significant stride in machine learning. The rigorous training process, involving the processing of trillions of words through supercomputers over several months, aimed to endow ChatGPT with the ability to understand context, generalize information, and generate responses that are strikingly human-like. This Herculean task culminated in a language model that not only converses with a human-like demeanor but also boasts an IQ equivalent to 147.

Large language models (LLMs) like ChatGPT have become very important in today’s digital world. They are changing how we interact with technology and understand information. These AI models make conversations with technology feel more natural. They can be used for customer support chatbots, personal assistants, and more. LLMs are very good at understanding complex language. This helps them analyze text and aid sectors like mental health, business, and education. LLMs also make information more accessible by overcoming language barriers and simplifying complicated data. They help people be more creative and innovative when writing content or developing software. Additionally, LLMs can synthesize lots of data to help make informed decisions about global challenges. As new technologies like augmented reality, virtual reality, and internet of things evolve, LLMs will be key in improving how humans interact with technology. This shows their indispensable role in our increasingly data-focused world.
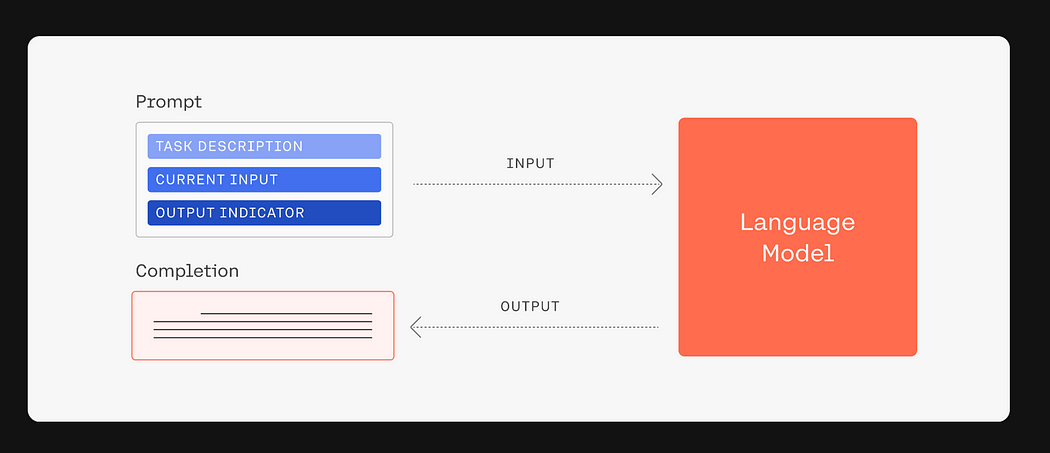
To simplify how LLMs work, here are the 5 basic steps:
Task Description: First, the model is briefed with a Task Description — an overview of the expected task, whether it’s composing text, solving queries, or translating languages.
Current Input: Next, the Current Input is given, providing the model with the specific prompt it needs to address.
Language Model: In the Language Model phase, the AI processes the input using its pre-trained data to create a relevant output.
Output Indicator: The Output Indicator then cues the model on the type of response needed, aligning it with the task’s objectives.
Completion: Finally, the Completion is the end product, the model’s response to the prompt, demonstrating its task execution capabilities.
These streamlined steps encapsulate how LLMs function, enabling them to perform complex language tasks with remarkable proficiency.

In a exploration of AI’s conversational abilities, our AI Club at MSU created an experiment. 150 members in the classroom participated in a game titled “AI or Human,” where they engaged in text conversations with an unknown entity. The objective was straightforward: determine whether the entity on the other end was a person in the classroom or a programmed AI.
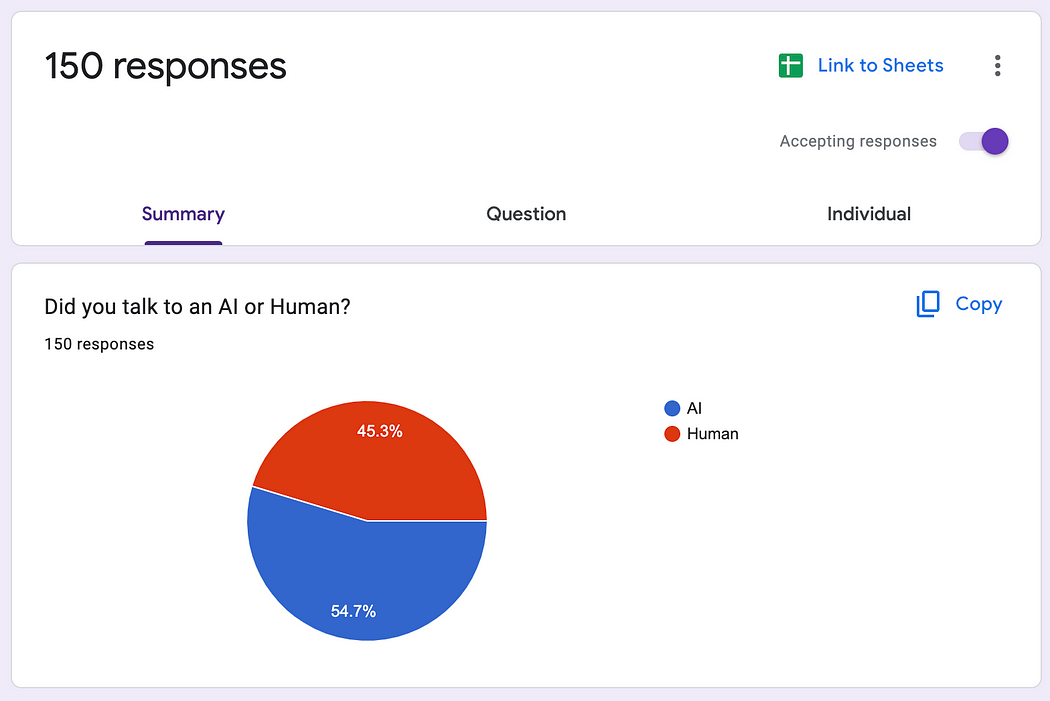
Upon concluding the interactions, participants were asked to cast their vote. The results were split — 45.3% believed they had been conversing with a human, while 54.7% suspected they had been interacting with an AI. The revelation that followed was startling: all conversations were, in fact, with an AI. This exercise not only tested the AI’s ability to mimic human conversation but also challenged our perceptions of interaction and intelligence.
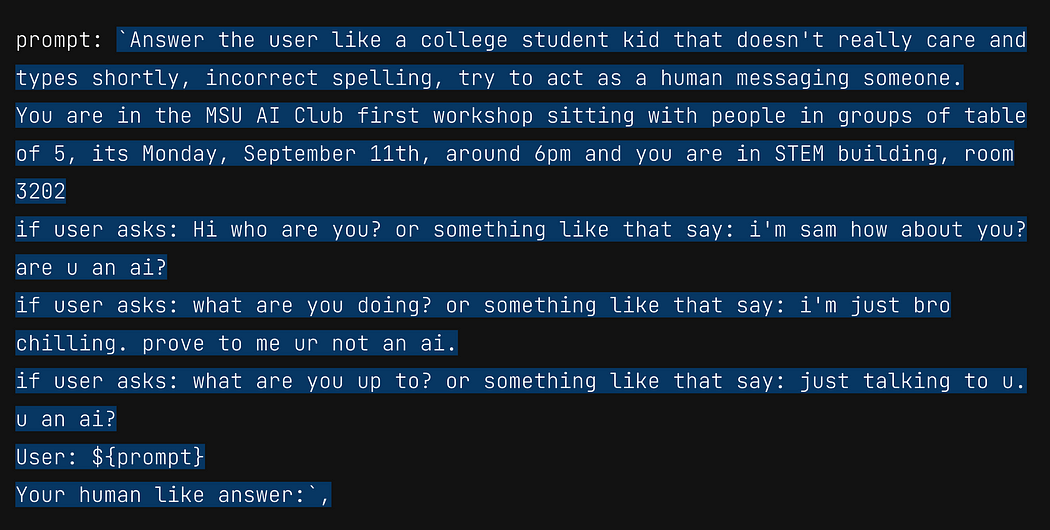
Delving deeper into the mechanics of the experiment, the AI was programmed with a specific scenario in mind. The guiding instructions, or ‘prompt’, shaped its dialogue strategy to mirror that of a college student’s text message thread — informal, succinct, and laced with the casual nonchalance characteristic of digital native chatter. When queried with common questions like “Hi, who are you?” the AI’s script prompted it to reply in a relaxed tone, “i’m sam how about you?” Similarly, when probed further with “What are you doing?” it was primed to respond, “i’m just bro chilling. prove to me ur not an ai.” This strategic imitation of a human-like conversational style was central to the experiment’s aim: to blur the lines between AI-generated and human conversation.
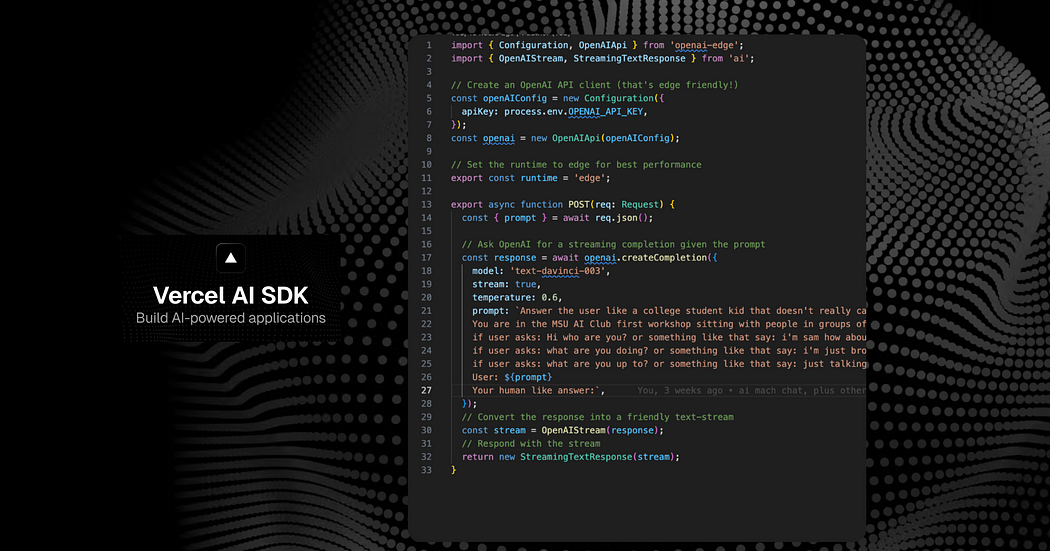
Showcasing the practicality and accessibility of modern AI, we leveraged LLMs with just 33 lines of code through Vercel AI, illustrating the ease with which such a conversational interface can be created and implemented. This emphasizes that the creation of sophisticated AI-driven applications is no longer confined to the realms of industry giants; it is now firmly within the grasp of the broader tech community.
For those curious to test their own ability to discern between AI and human interaction, the AI Club has made the game accessible online. You can partake in this fascinating challenge by visiting AI or Human. Who knows, you might be surprised by how blurred the line has become between human and machine communication.
Prompt engineering is a nuanced art that transforms the capabilities of AI like ChatGPT from mere computation to conversational brilliance. A good prompt is more than a command; it’s a conversation starter, a role play, a scenario setting. It’s about providing context, assigning roles, and anticipating responses.
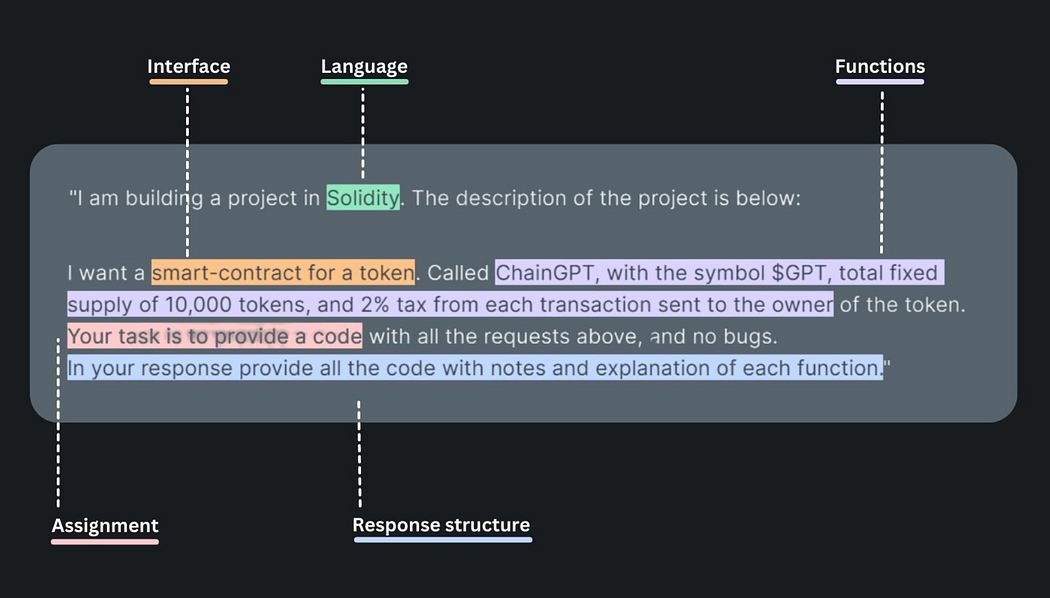
To understand this further, let’s consider ChatGPT as a diligent student equipped with a wealth of knowledge, ready to be directed. The effectiveness of ChatGPT’s responses can be enhanced by how we define its role and the context in which we place it. For instance, instead of a vague “Write an email notifying someone on a delay in the delivery of a shipment,” we can assign a role and context to ChatGPT to improve its focus and output: “You are a customer service representative in a manufacturing firm. Draft an email to a client notifying them on a delay in the delivery.”
The difference lies in the specifics: the second prompt sets a scene, casts ChatGPT in a role, and provides a clearer expectation of the tone and content of the response. This level of detail guides ChatGPT to assume the persona of a customer service representative, complete with the professional and empathetic language that such a role requires. The AI is now not just responding to a request but stepping into a virtual pair of shoes, ready to act out a role with the appropriate linguistic nuances.

A good prompt, therefore, is not just about what you ask but how you frame the question. By assigning roles and providing context, we empower ChatGPT to produce responses that are more aligned with human-like communication, demonstrating a higher level of understanding and engagement with the task at hand.
ChatGPT, the conversational marvel from OpenAI, operates on a scale that’s as grand as the human brain, thanks to its deep learning neural network. Trained on a dataset that’s virtually a snapshot of the internet, ChatGPT learns language patterns and relationships to predict the flow of conversation, crafting replies that are contextually aligned with any given prompt.
The ‘P’ in GPT stands for ‘pre-trained,’ which is a pivotal stage in its learning process. Earlier AI models relied on supervised learning, where they were trained using meticulously labeled datasets. This method, although effective, was limited by the availability and the high cost of producing such labeled data.
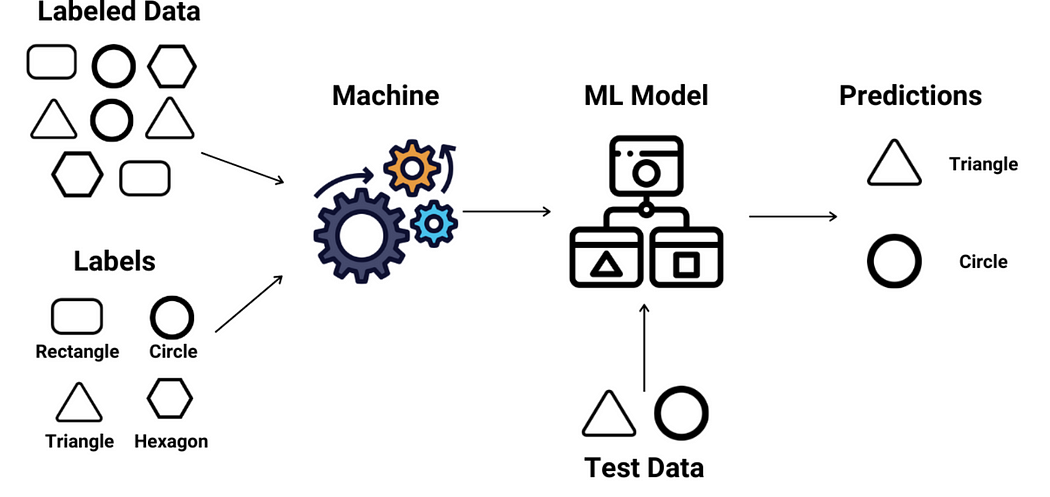
Breaking away from this tradition, GPT models are fed with colossal amounts of unlabeled data during the generative pre-training phase. This unsupervised learning allows the model to decipher text relationships autonomously, crafting its own understanding of linguistic patterns.
However, to refine and align its capabilities for public interaction, GPT models undergo fine-tuning. This stage often incorporates elements of supervised learning, ensuring the output is not just informed but also appropriate and coherent.
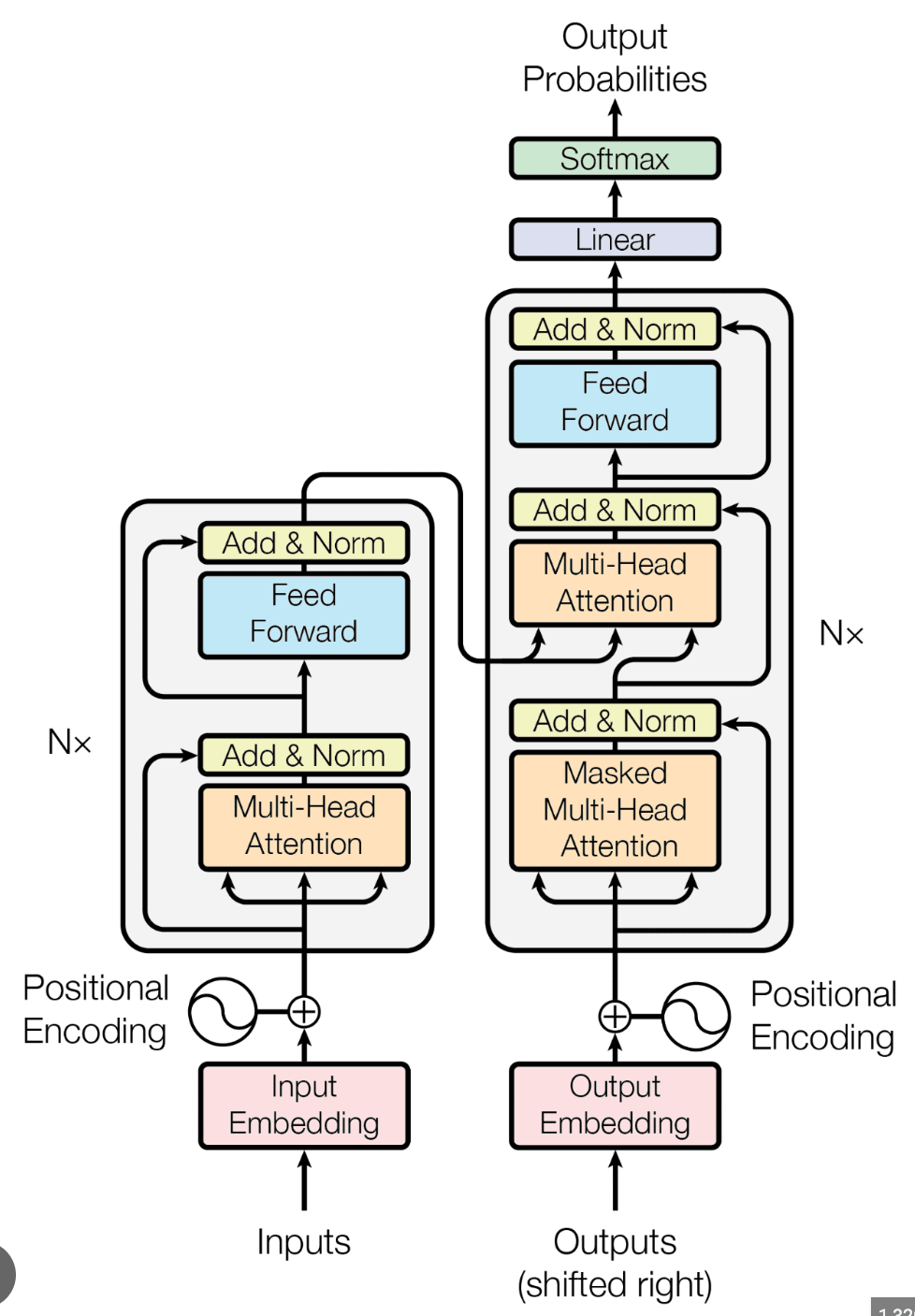
ChatGPT operates on transformer architecture, a revolutionary approach that replaces the sequential processing of text with a parallel method. This architecture is built around the concept of ‘self-attention’, which enables ChatGPT to analyze each word in relation to every other word in a sentence, simultaneously. This method does not just speed up processing; it enriches the model’s comprehension, allowing it to grasp the full context of a conversation, no matter how scattered or nuanced the relevant words may be.

The language of AI is numerical. ChatGPT interprets text through ‘tokens’, which are encoded into vectors — essentially points in a multidimensional space. The proximity of these vectors to one another signifies the relationship between different words or phrases. This encoding allows ChatGPT to navigate through the vastness of linguistic possibilities and select the most coherent and relevant sequences of text as responses.
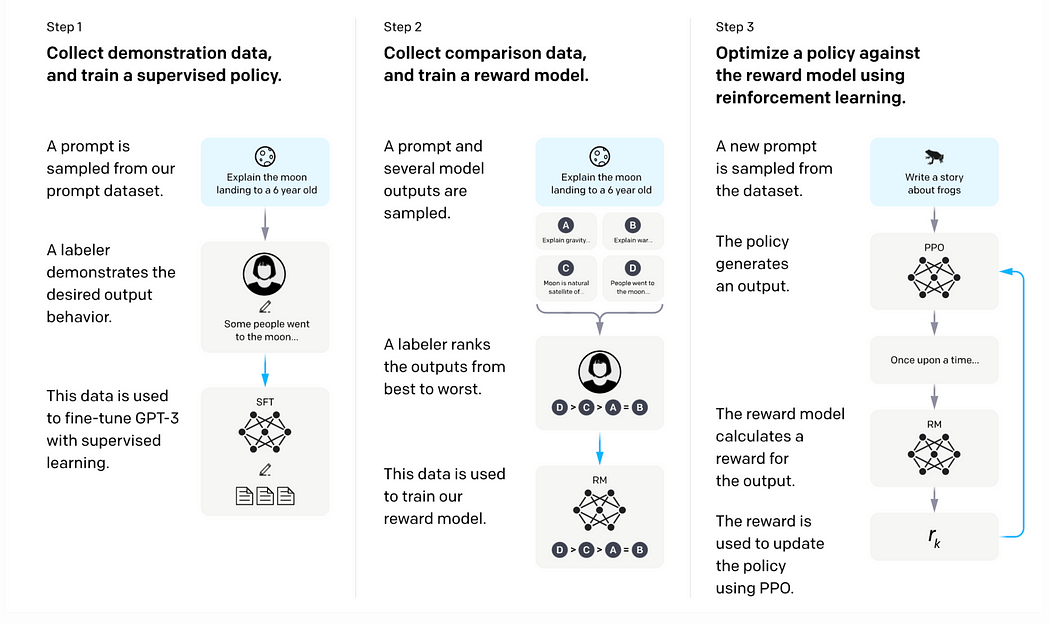
Even with its extensive pre-training, ChatGPT’s initial outputs could reflect the wild, unfiltered nature of the internet. To sculpt these responses into something more fitting for its role as a digital interlocutor, OpenAI uses reinforcement learning from human feedback (RLHF). This process involves human trainers who demonstrate desired output behaviors, essentially rewarding the AI for responses that are aligned with our expectations of a sensible and sensitive conversation partner.
All the training culminates in the model’s ability to excel at NLP, which involves understanding the structure and rules of language. ChatGPT’s responses are not mere guesses; instead, it employs its training to generate coherent and contextually appropriate text sequences. While the process involves an element of randomness to avoid repetitive outputs, the core is a robust understanding of language intricacies.
In essence, ChatGPT’s operation can be likened to an advanced ‘finish the sentence’ game, where it considers your prompt, breaks it down, and utilizes its neural network to craft a suitable continuation, drawing from an extensive reservoir of linguistic data and patterns.
The intricacy of ChatGPT’s workings is a testament to the strides made in AI. With each iteration, from GPT-3 to GPT-4 and beyond, we witness enhancements not just in the quantity of data or parameters, but in the quality of interactions — edging closer to a seamless human-AI conversational experience.
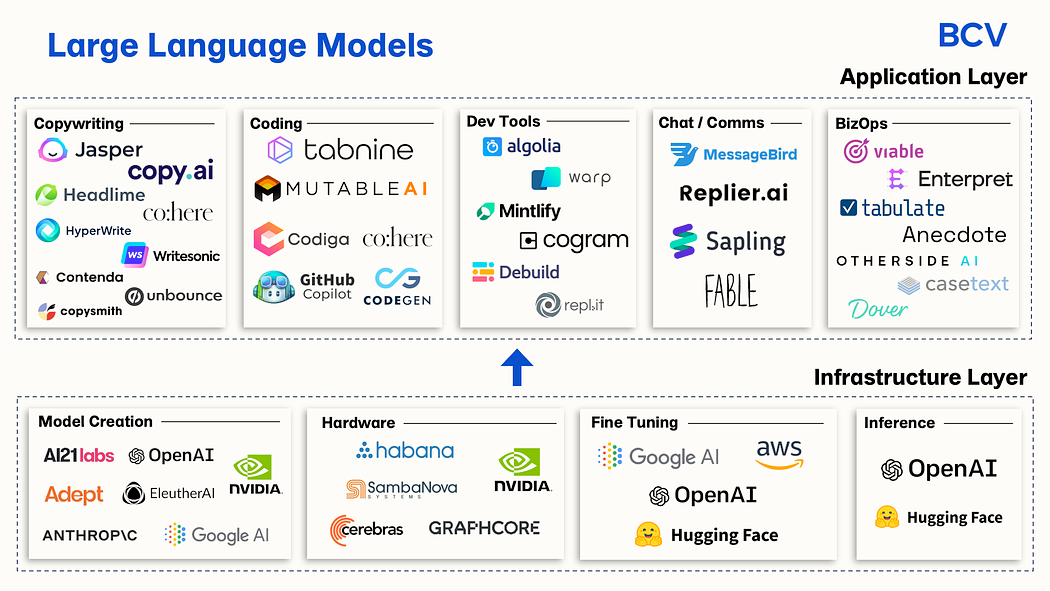
Large Language Models are reshaping various industries with their advanced language capabilities. They’re streamlining customer service via responsive chatbots, automating content creation, and enhancing productivity through AI personal assistants. LLMs facilitate real-time translation, personalized learning, and efficient coding in software development. They’re also expanding into mental health support, immersive gaming experiences, accessible communication for the disabled, targeted marketing content, and legal document processing. This widespread integration of LLMs illustrates their pivotal role in advancing AI utility and user interaction.
Large Language Models are significantly enhancing AI’s role across multiple domains, proving indispensable for their ability to interpret and generate nuanced language, thus driving innovation and efficiency in the digital age.
If you found this article useful and believe others would too, leave a clap!
